

Today, we managed to run our test pong program on the pipelined redesign of our CPU processor. Pipelining the CPU was a major step towards implementing out of order processing and a cool technical challenge to think about. First, I want to explain a little bit about what pipelining is and why our pipeline isn't the standard 5 stage pipeline you see from university projects.
Pipelining Is Awesome
For our first iteration of the CPU, each instruction had to go through 3 different stages.
- Fetch / Decode
- Execute 1
- Execute 2 (Sometimes)
Each stage took one CPU cycle. The issue was that the previous design had to wait for an instruction to finish each stage before another instruction could be handled.
One thing we can notice is that while an instruction is completing the Execute 1 stage, nothing is being done in the Fetch / Decode or Execute 2 stages! What if we just start processing another instruction right away? This is the idea of pipelining, and it allows us to process multiple instructions at once as we wait for each instruction to completely finish computing.
So, I redesigned the processor stages into a 6 stage pipeline.
- Fetch
- Decode
- Register File Read
- Execute 1
- Execute 2
- Register File Writeback
Each pipeline stage is a module that holds the information it needs to process. That way, an instruction can be computed in Execute 1 while another instruction is reading from the register file in Register File Read. Assuming everything is nice and rosy, we can be processing 6 instruction at once. Unfortunately, not everything is rosy all of the time. There are some tricky situations we need to watch out for.
Dealing With Hazards
Read After Write Hazard
Imagine we have this code:
add x2, x1, x2 # x2 = x1 + x2
add x3, x1, x2 # x3 = x1 + x2The first instruction writes to the x2 register. The second instruction reads from the x2 register. We have a devious problem! If we look back at our pipleline, it might look something like this:
- Fetch
- Decode
- Register File Read -
Instruction 2 - Execute 1 -
Instruction 1 - Execute 2
- Register File Writeback
Then we skip forward a bit:
- Fetch
- Decode
- Register File Read
- Execute 1
- Execute 2 -
Instruction 2 - Register File Writeback -
Instruction 1
Did you catch that? Instruction 2 reads from the register before Instruction 1 writes its result to the register.
In order to handle this, the processor keeps track of what registers are going to be modified in the near future. Then, if it encounters an instruction that is reading from these registers, it tells the pipeline stages Fetch, Decode, and Read to reset and start again. By the time the instruction reaches the Read stage again, all of the modifications to the registers will have gone through and now have the correct data!
You'll notice as you continue to read that our default strategy for encountering issues like this is to flush. That means we just tell all of the pipleine stages before us to reset and start again from an earlier point in the program. I'll explain how we track which data is valid and where to reset to when flushing here after I finish explaining the rest of the hazards.
Jump Hazard
We also need to be careful that our program jumps or branches. By default, the processor expects the next desired instruction to be directly after one another. The instruction pointer in the core always preemptively updates to instruction_pointer + 4 before we have even begun decoding the instruction we are fetching from memory. We need to do this to be able to keep passing new instruction into the pipeline. Otherwise, we would have to wait for an instruction to finish executing, defeating the entire point of implementing a pipeline in the first place!
Jump instructions and conditional branches break this assumption. To make matters worse, we only actually know where they want to jump once they reach the Execute 1 stage. The means by the time we know where we need to go, there's already 3 potential incorrect instructions filling up the Fetch, Decode, and Read stages.
- Fetch -
Wrong Instruction - Decode -
Wrong Instruction - Register File Read -
Wrong Instruction - Execute 1 -
Jump Instruction - Execute 2
- Register File Writeback
The fix of course, just like the RAW (read after write) hazards, is to flush those three earlier stages and start again from where we actually want to jump.
Memory Write Hazard
Memory hazards similar to the RAW hazards, but we need to deal with them for a different reason. I've designed the processor with a strict constraint on io to memory to make sure we can map the processor easily to an FPGA for testing. This means we can only have two read / write ports to our processor memory. One io port is dedicated to loading instructions from memory. The other is used for any instructions that need to deal with memory such as loads and stores.
Here's where I get to explain why we have two execute stages. Often on FPGAs, there are chunks of memory called BRAM. These BRAMs have one cycle of latency from when you read and write to them. Additionally, in order to facilitate loading a full word (or 4 bytes) from memory for instructions, our BRAM is paritioned into addressable words, not addressable bytes. That means if we want ot modify a single byte, we need to read a full word, apply the modification in the word, and then write the full word back.
That first Execute 1 stage is for using the second memory io port to read from memory. Then next Execute 2 stage is for applying the modification to the value and writing back to memory.
Now we have a problem, what if we have two different instructions in Execute 1 and Execute 2 that need to access memory? We only have one io port for both of them. The fix, of course (you guessed it), is to flush. Every stage, including and before Execute 1, is flushed when Execute 1 detects a memory read instruction right after it handles a memory write instruction.
Tracking Validity and Flushing Properly
When part of our pipeline flushes, information is still tracked in the pipeline stages. We need a way to know which parts of our pipeline contain valid instructions. The way the processor handles this is by implementing a valid signal for each pipeline stage. This valid signal is passed along with the data. Most computation will be completed regardless of wether valid is set or not, but important effects such as writing to registers, triggering flushes, or triggering jumps will only happen if valid is set within that stage.
Another very important piece of information passed along the pipeline stages is the program_pointer location for each instruction. Program jumps are triggered within the Execute 1 stage. The real program pointer in the processor core is constantly changing and will most likely be very different than the instruction's true location when a jump instruction reaches the Execute 1 stage. So, we can pass the instruction pointer value when the instruction was fetched along the pipeline stages. When jump executes offsets from this passed instruction_pointer instead of the instruction pointer in the core.
Testing the Pipelined CPU
To help test running larger programs on the CPU, I wrote a Verilator script that reads the VGA output and writes to an image file so that I can see the frames as they are created.
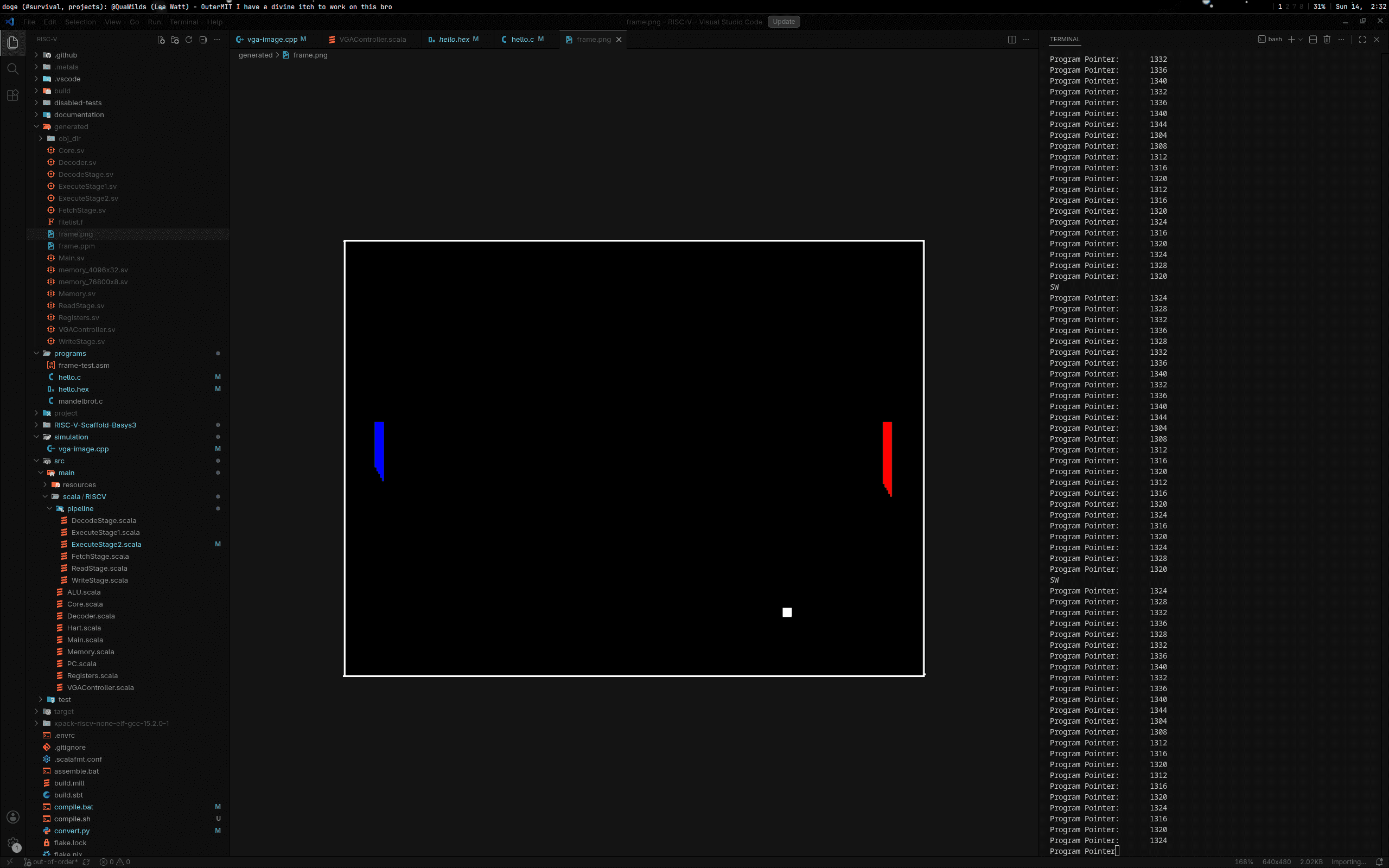
It runs fast enough to help me diagnose some issues, but of course we want realtime visuals (because that's always insanely cool to see).
Peter Schmidt-Nielsen from Saturn Data graciously sent us some FPGAs they no longer needed: 2 custom Artix 7 boards and 2 Kintex 7 PCIE cards. Using one of the custom Artix 7 boards, we programmed the board with our design and hooked up a VGA cable to one of the TVs we found that took VGA as input.

How This Brings Us Closer To Out of Order
Ideally, an out of order processor is also pipelined, just some of the pipeline stages in the middle change the assumption we can make about the timing and ordering of instructions.
Achieving a fast out-of-order CPU is the next design milestone. Currently, the design assumes a fixed known latency for memory operations. While this works fine when we have BRAM, there's only so much BRAM on our FPGAs. We need to upgrade to DDR memory, which has variable latency. Out of order will allow us to handle this variable latency more elegantly. This also means we'll have enough memory to try running DOOM. :)
Thank you for checking out our CPU! You should also check out my friend Armaan Gomes, who wrote a cool post on accelerating a feed foward neural network.